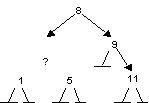|
Центр оптико-нейронных технологий
ФГУ ФНЦ НИИСИ РАН |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Деревья поискаПусть бинарное дерево организовано так, что для каждого узла ti все узлы левого поддерева меньше ti, а все узлы правого поддерева больше ti. Например,
Такое дерево называется деревом поиска. Поиск заданного элемента в таком дереве может быть осуществлен простой нерекурсивной процедурой без необходимости выполнять полный обход дерева. Пусть нужно в дереве поиска найти узел со значением x. Алгоритм поиска следующий:
Если по окончании поиска p=nil, то искомого узла в дереве нет, иначе p указывает на искомый узел. Данный алгоритм можно реализовать в виде функции: Функция возвращает указатель на искомый узел или nil, если такого нет. В том случае, если дерево поиска, содержащее n узлов, сбалансировано, то его высота не превышает log2n, и поиск заданного узла займет не более log2n шагов. Поэтому хране-ние больших объемов информации в виде деревьев поиска предпочтительнее, чем в виде списков, поскольку в списке, содержащем n узлов, в худшем случае при поиске придется выполнить n шагов по списку, а в среднем - n/2. Иначе говоря, сбалансированные деревья поиска по эффективности поиска близки к отсортированным массивам, и при этом могут динамически изменять размер. Построение дерева поиска (включение в дерево поиска)Пусть задана некоторая последовательность значений. Необходимо из них построить дерево поиска. Если не ставить требование, чтобы дерево было сбалансированным, то алгоритм построения дерева поиска очень прост:
Например, для последовательности 8, 9, 7, 3, 5, 11, 2, 15, 10, 6, 4, 13, 1, 19 дерево будет выглядеть так:
Процедура для вставки узла в дерево поиска следующая: Если в дереве уже есть узел с таким значением, то добавление нового узла не производится. Пример использования процедуры: Использование деревьев для сортировкиЕсли выполнить b-обход (ЛКП) дерева поиска, то получим отсортированную последо-вательность. Например, b-обход дерева из предыдущего примера даст последовательность 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 15, 19. То есть деревья поиска можно использовать для сортировки. Однако при сортировке в исходной последовательности значений могут быть повторы. Например, последовательность 8, 9, 7, 8, 3, 5, 3, 11, 9, 8, 15, 1, 15, 10. Поэтому необходимо изменить процедуру вставки элемента в дерево поиска так, чтобы новый элемент включался даже если он уже есть в дереве. Иначе говоря, случай x=p^.info обрабатывать так же, как и случай x>p^.info. Процедура используется так же, как InsertNode1. Для приведенной выше последовательность значений с использованием данной процедуры будет построено следующее дерево:
b-обход данного дерева даст последовательность 1, 3,
3, 5, 7, 8, 8, 8, 9, 9, 10, 11, 15, 15.
Сортировку с использованием деревьев выгодно использовать в тех случаях, когда заранее неизвестно число сортируемых элементов. При этом, по сравнению со списками, процесс вставки элементов для дерева будет выполняться быстрее, в особенности если дерево будет близко к сбалансированному. Использование деревьев для построения частотного словаряПусть задана некоторая последовательность значений, которые могут повторяться. Необходимо подсчитать, сколько раз каждое значение входит в последовательность. Иначе говоря, нужно построить частотный словарь. (Например, для заданного текста подсчитать, сколько раз входит в него каждое из слов). Если диапазон возможных значений в последовательности конечен и не слишком велик, то это можно сделать с помощью массива, каждый элемент которого представляет собой счетчик для соответствующего значения. Для каждого очередного значения последовательности увеличивается значение его счетчика. Однако если диапазон возможных значений бесконечен или конечен, но слишком велик (например, количество разных слов в тексте), то мы не можем использовать массив, так как неизвестна его длина. В этом случае задача построения частотного словаря может быть решена с помощью дерева поиска. К каждому узлу дерева добавляется поле счетчика. Для каждого очередного значения в последовательности осуществляется его поиск в дереве. Если такого значения в дереве еще нет (то есть оно встретилось в первый раз), в дереве создается узел, полю счетчика которого присваивается значение 1. Если узел с таким значением найден (значение встретилось уже не в первый раз), то поле счетчика этого узла увеличивается на 1. После завершения последовательности значений можно выполнить b-обход построенного дерева, распечатывая для каждого узла
его значение и величину счетчика, в результате чего получим отсортированный
частотный словарь. Процедура используется так же, как InsertNode1. Например, для последовательности символов фразы <построение частотного словаря> (без учета пробелов) будет построено следующее дерево:
Выполнив b-обход этого дерева, получим частотный словарь:
Исключение из дерева поискаИсключение узлов из дерева поиска следует проводить так, чтобы для каждого из оставшихся узлов сохранялось свойство: значения в левом поддереве были меньше его значения, а значения в правом поддереве - больше (либо равны). То есть свойство отсортированности дерева должно сохраняться. При исключении узла из дерева поиска возможны три случая. Первые два из них простые и затрагивают только непосредственного предка удаляемого узла, третий случай сложный и затрагивает несколько узлов. Случай 1 (простой). Исключаемый узел не имеет поддеревьев (llink=nil, rlink=nil). В этом случае узел просто удаляется, а соответствующая связь у непосредственного предка становится равной nil. Например, из следующего дерева удаляется узел 1:
Случай 2 (простой). Исключаемый узел имеет только одно поддерево (llink<>nil и rlink=nil) или (llink=nil и rlink<>nil). В этом случае узел удаляется, а его единственное поддерево перемещается на место удаленного узла (поднимается на уровень выше). Например, из следующего дерева удаляется узел 7:
Случай 3 (сложный). Исключаемый узел имеет оба поддерева (llink<>nil и rlink<>nil). Просто удалить этот узел нельзя - останутся два его поддерева, переместить на уровень вверх мы можем только одно. Например, если из следующего дерева удалит узел 3, то неясно, что делать с его поддеревьями:
Решение заключается в следующем: на место исключаемого узла поместить либо самый правый узел его левого поддерева (предшественник при b-обходе), либо самый левый узел его правого поддерева (преемник при b-обходе). Например, удаляя из следующего дерева узел 9, имеющий оба поддерева, помещаем на его место предшественника - узел 8:
Здесь вспомогательная процедура Move рекурсивно спускается вдоль правой ветви левого поддерева исключаемого узла, находит самый правый узел (r) этого поддерева, перемещает его значение на место исключаемого узла, а возможное левое поддерево узла r - на место самого r. После ее выполнения q указывает на тот узел, который нужно физически удалить (то есть на тот узел, в котором до выполнения Move находилось значение-предшественник). Иначе говоря, в третьем случае физически удаляется не исключаемый узел, а узел-предшественник, предварительно переместив его значение на место исключаемого значения. Пример использования процедуры. Пусть root указывает на корень дерева поиска. Тогда, например, для удаления из дерева значения 9, нужно вызвать: Если в дереве будет несколько узлов со значением 9, то процедура исключит первый найденный узел с таким значением. Литература
Copyright c2000-2002 Михаил
Марковский |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© Центр оптико-нейронных технологий
Федеральное государственное учреждение Федеральный научный центр Научно-исследовательский институт системных исследований Российской академии наук All rights reserved. 2016 г. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||